
Bonjour à tous, aujourd’hui je vous partage un bug que j’ai rencontré avec un instance Splunk il y a quelques temps de ça. L’erreur en question était celle-ci : « The percentage of small buckets (40%) created over the last hour is high and exceeded the yellow thresholds (30%) for index« . J’ai mis un moment à la détricoter.

Après quelques recherches (ici, là), j’ai fini par identifier la root-cause : des logs sui arriveraient avec « trop de retard » par rapport à leur date réelle d’émission. Ce délai forcait Splunk, qui range les données dans les Bucket de manière temporellement ordonnée, à recréer des bucket pour ces évènements car ceux correspondant à cette plage temporelle avaient été fermés.
A la recherche des logs pétés
A partir de mon erreur, je me lance donc dans le SPL ci-dessous et effectivement j’ai bien une des sources de logs qui arrivent avec des latences pas normales.
index=<monindex>
| eval latency=_indextime-_time
| stats min(latency),
max(latency),
avg(latency),
median(latency)
by index sourcetype host
| sort - "avg(latency)"
Du coup j’ai gratté un peu sur l’hôte en question et il s’avère qu’on a régulièrement des grosses latence à l’indexation, à minuit. Pour la requête ci-dessous :
vendor_time: c’est l’heure du log sur la machine qui l’a envoyée, présente dans le log._time: c’est l’heure de réception sur le serveur rsyslog / UFW._indextime: heure d’écriture côté indexeur
index=proxy host="gotproblem" | eval vendor_time=vendor_time/1000 | eval latencyindex=_indextime-_time | eval latencyreceived=_indextime-vendor_time
| timechart min(latencyindex), max(latencyindex), avg(latencyindex), median(latencyindex), min(latencyreceived), max(latencyreceived), avg(latencyreceived), median(latencyreceived) span=15min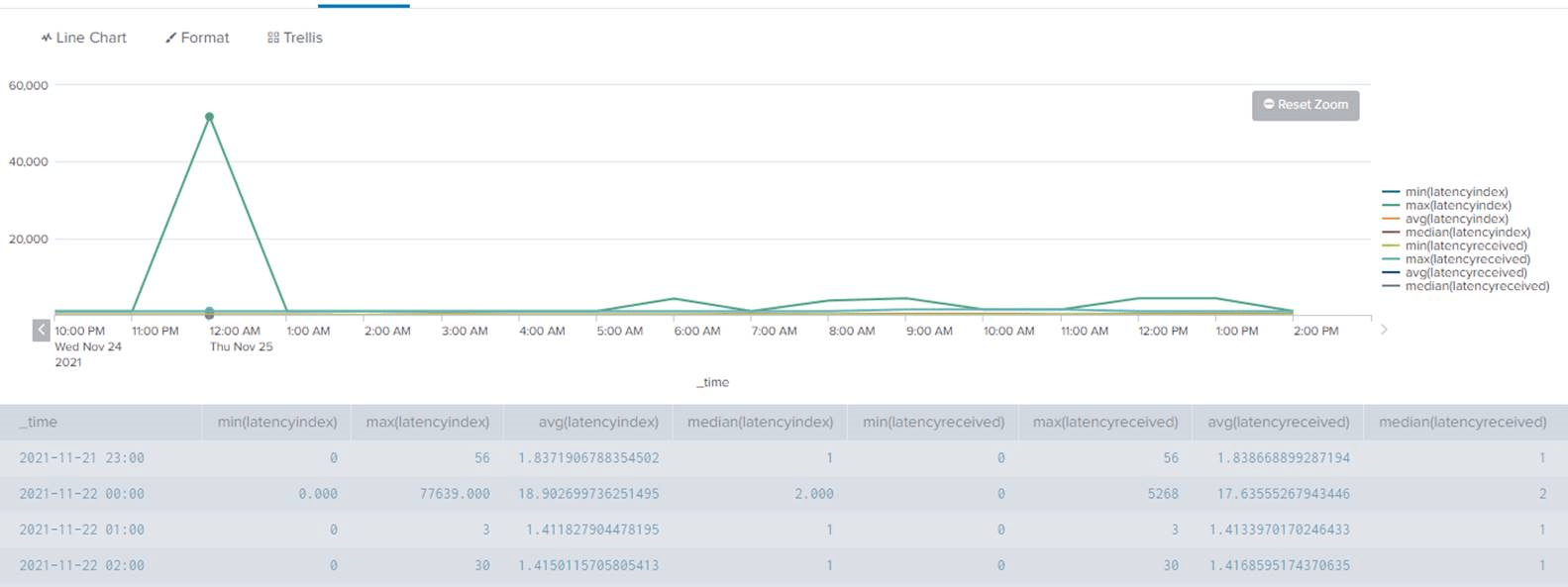
Cela semble indiquer qu’il se passe un truc de temps en temps à minuit sur cette passerelle proxy, ou plutôt sur l’UFW puisque c’est la colonne latencyindex qui explose et pas latencyreceived.
Les logs pétés
Donc j’ai poussé l’investigation avec une dernière recherche pour essayer de toper les logs qui posent problème :
index=proxy host="gotproblem" | eval vendor_time=vendor_time/1000 | eval latencyindex=_indextime-_time | eval latencyreceived=_indextime-vendor_time | where latencyindex > 10000 | eval vendor_time=strptime(vendor_time,"%Y-%m-%d %H:%M:%S") | table _time _indextime vendor_time latencyindex latencyreceived _raw
Bon la je vous met pas de capture d’écran ce serait des logs de mon ancien taf, ils seraient pas d’accord… :-). Vous allez devoir me faire confiance. Mais en gros, j’ai découvert qu’on avait certains logs qui était tronqué du début de la ligne. Genre au lieu d’avoir ça :
2021-11-25T14:10:41+01:00 hostname log,content,etc.
J’avais ça :
00 hostname log,content,etc.
Du coup, l’indexeur qui recevait les logs sans le horodatage du syslog en début de ligne n’arrivait pas donner une date à l’évènement et le placait à minuit par défaut. Cela forcer l’indexerur à rouvrir des buckets plutot que ranger l’évènement dans le bucket de cette place de temps.
Bon a identifié la cause du bug, pas encore compris le pourquoi mais au moins on sait ce qui cause le warning.
La résolution facile
Alors la première résolution a été « assez simple », Il a suffit de changer dans la configuration Splunk de ce sourcetype le champs utilisé pour le _time (dans props.conf). En effet, j’avais laissé (par fainéantise ? je ne sais plus) l’extraction du champs sur l’en-tête syslog et pas sur le vendor_time dans le log. Dans la pratique la différence se comptait en « pas grand chose du tout », ce qui ne posait pas de problème pour la supervision et simplifiait l’intégration des logs.
Au final, j’ai remplacé cette approche par une extraction « propre » du timestamp vendor_time dans le log. Pour éviter à Splunk de mettre minuit par défaut quand le timestamps syslog était vide.
En effet de bord sympa, ça changer le comportement par défaut de Splunk qui dans le cas ou le vendor_time ne serait pas présent non plus, met alors la _time à l’heure de l’indexation au lieu de minuit (la coupure des logs ayant lieu à un endroit aléatoire dans la ligne). Problem Solved.
La root cause moins facile
Par contre on a pas répondu à la question du pourquoi certains logs sont coupé en deux. Alors, je peux pas complètement vous répondre. On a passé un long moment avec le support Splunk (merci à eux) à détricoter l’ensemble dans le détails… pour se rendre compte que le soucis n’était pas côté Splunk mais bien côté rsylog. A partir de là, ils m’ont recommandé de passer par l’App « Splunk Connect for Syslog » plutôt que rsyslog. Sauf que pas possible facilement dans mon environnement.
Comme je disais, c’est rsyslog qui pour une de mes source de log avait décider de « couper » quelques lignes (genre quelques dizaine sur des millions de lignes par jour), au hasard, et d’écrire le reste sur la ligne suivante du fichier supervisé par Splunk. Le truc, c’est que j’ai rien trouvé qui ressemble de près ou de loin à ce bug sur les z’Internet, et la doc/support de rsyslog est un peu… ésotérique ? 🙂 Comme en plus, on utilisait un serveur pas tout jeune, il aurait fallu commencer par patcher le serveur et rsyslog.
L’autre option serait de passer par un syslog-ng, voir si le problème est le même… mais je n’ai pas eu le temps de tester encore.
Conclusion
Bon voilà, au final j’ai pas tout détricoter sur mon erreur « The percentage of small buckets (40%) created over the last hour is high and exceeded the yellow thresholds (30%) for index« . Néanmoins, j’ai trouvé que le chemin d’analyse côté Splunk que j’ai décrit ci-dessus méritait d’être partagé malgré tout. Et peut-être même que quelqu’un aura le même problème avec rsyslog et finira par me donner la solution ! En attendant moi comme je ne bosse plus là bas, je n’aurais surement pas le fin mot de l’histoire.
J’espère que ça en aidera quelqu’un. Geekez bien !

Une petite requête que j’utilise pour visualiser les rotation de bucket (hot to warm) et leur raison : init_roll(=reboot), size_exceeded(=OK si pas trop fréquent), lru(=problème de small bucket). A lancer sur un mois.
index=_internal HotBucketRoller idx=mon_index | eval nb=coalesce(evicting_count, 1) | timechart sum(nb) by caller
Merci pour le partage d’info Cédric !