

Bonjour à tous, aujourd’hui je voulais vous parler de l’archivage avec Amazon S3 Glacier. Au début je pensais faire un truc rapide, puis je me suis retrouvé à y passer un après-midi complet… Mais d’abord un peu de remise en contexte ! Je vous ai dit que je faisais un peu de photos en vacances et à mes heures perdues, non ? Rien de professionnel hein, mais un petit Nikon D600 avec un objectif 24-120 depuis 2012. Ce qui permet de se faire plaisir en plein format et sans se trimbaler 10 d’objectifs en permanence. Bref, ça fera bientôt 10 ans qu’on prend des photos avec ma douce moitié, tout se passait bien jusqu’à ce que je regarde la taille du dossier « photos » sur le NAS : 420Go pour 43 000 photos (quand on vous dit que les films de vacances : ça prend de la place à 30Mo la photo !).
La stratégie de Backup
Bon alors pas d’inquiétude, ma stratégie de backup est propre. Comme on trie nos photos après chaque sortie. Le dossier avec celles que je ne veux absolument pas perdre (4Go) est backupé proprement sur 2 emplacement local (à la maison sur un PC et le NAS) et un emplacement distant automatiquement (en datacenter, mais je n’ai que 100Go de disponible la-bas), d’ailleurs je me sert du code PS1 et FTPS dont je vous ai parlé la dernière fois. Du coup ça m’a fait me demander comment je pourrais archiver autant de données aujourd’hui sans racker une blinde.
Niveau objectifs de cet article, on peut considérer que mes besoins sont les suivants pour les critères habituels en sécurités :
- Disponibilité : faible, j’ai déjà mes données en local. Je cherche juste un service d’archivage, c’est pas grave s’il me faut un mois pour récupérer mes données.
- Intégrité : fort là, le moyen de stockage retenu doit me garantir que les données ne bougent pas : ne pas être sensible aux crytpolocker et à l’obsolescence du matériel par exemple.
- Confidentialité : moyenne, j’ai pas envie que vous accédiez à toutes mes photos de vacances. Il n’y a rien de compromettant pour au-dedans non plus (désolé, çà c’est ailleurs :-)). Si elles devaient leeker, je m’en remettrai.
- Traçabilité : faible, un peu dans la même veine que la confidentialité sur ce point.
Archive for the tramps
Bon on va pas y aller par 4 chemins, si vous chercher à faire du backup hors-site. Le plus simple c’est d’acheter un ou deux disques durs externes et de copier les données une fois tous les mois puis de le stocker ailleurs (chez vos parents, dans un casier au bureau, à sa banque dans un coffre, chez votre amante, etc.).
Niveau prix, à l’heure où j’écris ses lignes 1To en disque dur externe se trouve à environ 60€. Les HDD sont données pour une durée de vie de 5 ans (en général). On peut admettre qu’il nous en faut 2 en cas de panne et pour en laisser toujours au moins sur un site distant. Donc 2 x 60€ / 5 x 12 mois = 2€/mois.
Ce système répond bien à mes objectifs. Il à l’avantage d’être simple et implémentable par à peu près tout le monde et d’avoir une bonne garantie d’intégrité puisque hors ligne
Archive for the richs
La seconde option, c’est de louer de l’espace cloud en ligne par exemple chez Google One. C’est plus souple, mais c’est 3 à 5 fois plus cher sur 5 ans quand même. Plus fiable, et pour un budget fixe connu à l’avance le système répond bien aux objectifs.
Par contre, si on utilise les Apps de synchronisation local<->cloud on reste vulnérables aux ranswomwares à cause de la synchronisation. La complexité reste abordable pour M. et Mme tout le monde également.
Archive for the Geeks
L’option (il y en 450 000 possibles) dont je voulais vous parler aujourd’hui, c’est les services dédiés type Amazon S3 Glacier (et Deep Glacier) ou C14 Cold Storage chez Scaleway). L’archivage avec Amazon S3 Glacier c’est du « Cloud » low-cost dédié pour la sauvegarde de long terme. Les coûts annoncés sont autour d’un à deux euros par mois et par Teraoctet. Alors clairement on perd les non-geeks ici, car le service est accessible presque que via API. On remarquera quelques clients graphiques existent quand même : ici, là ou là.
Cela dit pour les barbu.e.s., c’est gérable au quotidien et mieux qu’une paire de disque à la main. Et ça atteint les mêmes objectifs, notamment la duplication sur plusieurs site. Du coup, c’est sur celle-ci que je vais me pencher aujourd’hui après cette (trop) longue introduction.
L’archivage avec Amazon S3 Glacier
Bon la première chose à faire c’est de vous créer un compte AWS puis de créer un compte pour l’API avec la partie IAM. C’est un peu pommatoire vue la quantité de service présent dans l’Interface. On se fait aussi un peu peur quand on met son n° de CB mais globalement ça se fait bien. Le seul point qui mérite que je documente par un screenshot ci-dessous est l’ajout des droits au nouveau compte d’API sur le module Glacier :
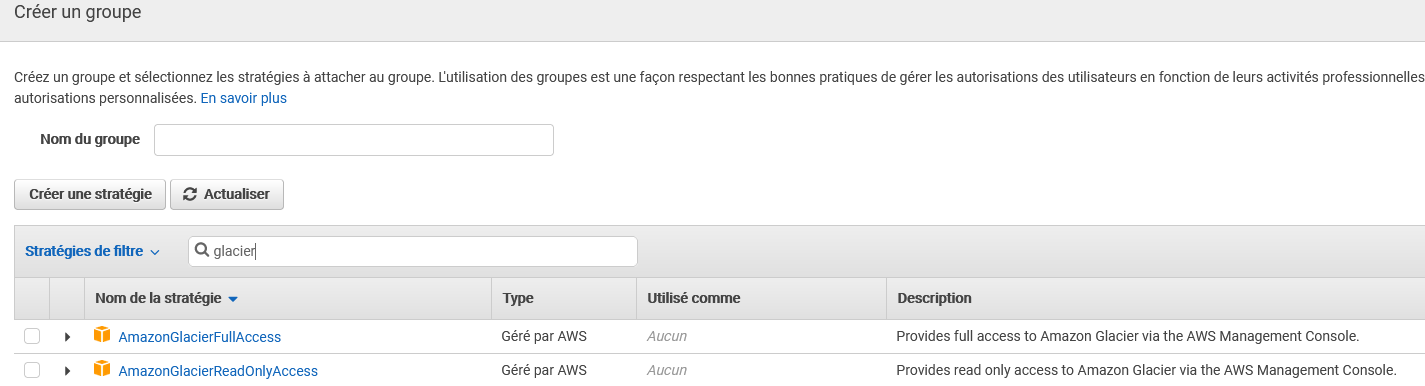
Coffres forts et archives dans Glacier
Avant de pouvoir développer un script, il faut comprendre que dans S3 Glacier les données sont stockées dans des coffres fort (ou vault) puis dans des archives séparées. En gros une archives c’est un fichier (zip, tgz, mkv ou png) avec un fichier de métadonnées à côté (32Ko fixe, de mémoire). Il est possible de faire une archive par fichier mais c’est peu efficient, donc mieux vaut utiliser des format compressés (zip, tgz, rar, 7z, etc).
Ensuite ces archives sont stockées dans des coffre-fort, vous pouvez en avoir jusqu’à 1000 par comptes. Les coffres permettent de gérer des stratégies d’accès différentes mais aussi de facturation ou de notifications. Vous noterez qu’il est possible de taguer les archives (unité de rattachement en entreprise, catégorie, n° de facturation,).
La première chose à faire est donc de créer votre coffre-fort :
Notez que lors de la création (et après dans paramètres), vous pouvez configurer le vault pour n’utiliser que les fonctions gratuite de l’offre.
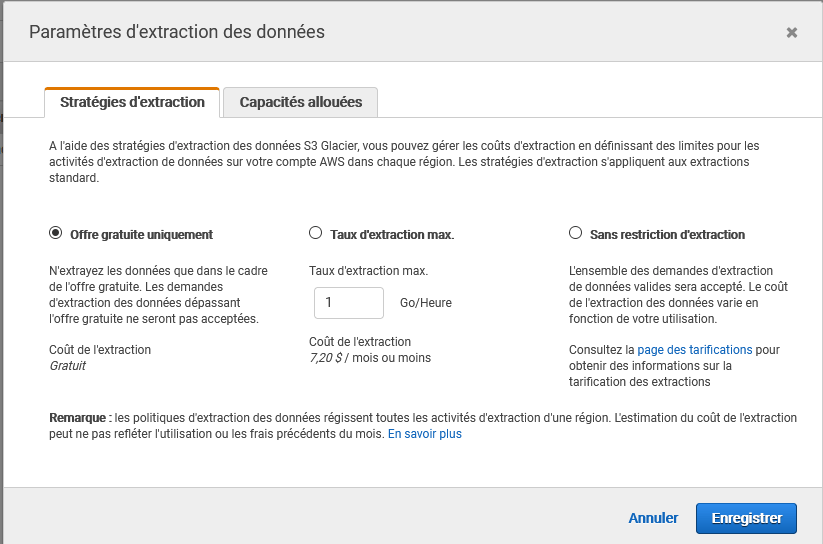
Faite bien attention à la « région AWS » où vous créer le vault (le datacenter si vous préférez) : la tarification change et on en aura besoin pour la suite :
Configuration du Module PowerShell pour AWS
Amazon sont sympa sur ce coup-là, ils ont déjà tout préparé pour nous et tout bien documenté (ici, là). Donc pour installer le module PowerShell dédié à Glacier on fait :
Install-Module -Name AWS.Tools.Installer Install-AWSToolsModule AWS.Tools.Glacier,AWS.Tools.S3
La 1ère chose à faire c’est de configurer les credentials d’accès par défaut :
$API_acces = 'ahahah' $API_secret = 'nanmévouycroivezvraimentvous' Set-AWSCredential -AccessKey $API_acces -SecretKey $API_secret -StoreAs "default"
Vous pouvez alors contrôler qu’ils ont été installé avec :
PS C:\> Get-AWSCredential -ListProfileDetail ProfileName StoreTypeName ProfileLocation ----------- ------------- --------------- default NetSDKCredentialsFile
Il faut ensuite régler la région (ou datacenter) correspondant à votre vault, utilisez la cmdlet Get-AWSRegion pour obtenir la liste et régler cette par défaut :
Set-DefaultAWSRegion -Region eu-north-1
PowerShell AWS pour Glacier
Bon on y est, « yapuka » comme dirait l’autre. On va commencer par lister nos coffres fort disponibles avec :
> Get-GLCVaultList CreationDate : 05/04/2021 18:48:53 LastInventoryDate : 01/01/0001 00:00:00 NumberOfArchives : 0 SizeInBytes : 0 VaultARN : arn:aws:glacier:eu-north-1:281798635338:vaults/Photos VaultName : Photos
Remarque, il est aussi possible de créer un Vault directement depuis l’API forcément
New-GLCVault -VaultName geekeries.org
pour uploader une archive dans notre Vault, il faut utiliser la CmdLet :
$res = Write-GLCArchive -VaultName Photos -File "test.zip" -Description '\\NAS\data\Photos\AWS\tests'
$resNotez : l’utilisation du champs description pour enregistrer où se trouvaient les fichiers initialement sur mon NAS, et pouf :
$res FilePath ArchiveId -------- --------- Z:\Photos\AWS\test.zip xEvQrscsP02rxlHW5hTsjCRzdr03Bj7-SY4ohdaA6u-8Kf_ilGqootfctJg523AkhEtdgSsnsZNhOpdEWwtkt2ZvGy__…
Notez précieusement cette archive ID, c’est lui qui vous permettra de récupérer le fichier par la suite.
InventoryRetrieval
Dans la cas où vous auriez perdu l’ID de votre archive (comme moi), pas de panique ! il est toujours possible de récupérer un inventaire de votre vault avec toutes les archives stockées. Ca prend juste plusieurs heures… 🙂
$Param = New-Object Amazon.Glacier.Model.InventoryRetrievalJobInput $Param = New-Object Amazon.Glacier.Model.InventoryRetrievalJobInput $Param.EndDate = '2021-04-06T18:00:00Z' $Param.Limit = 10 $Param.StartDate = '2021-04-05T18:00:00Z'
Puis
Start-GLCJob -InventoryRetrieval $Param -VaultName Photos -JobDescription 'test inventory retriaval' -JobType "inventory-retrieval" JobId JobOutputPath Location ----- ------------- -------- yyvnQ4O4hNLRpR5PQg3_UlKMSho3eII6bAKOc3X3vMK3UYE6yO_9IyxvR8UCkgO4_nShr6rUPPFg11ycRL262Lut48zl /281499635336/vaults/Photo…
Vous pouvez savoir si votre job est terminé avec la commande :
Get-GLCJobList -VaultName Photos Action : InventoryRetrieval ArchiveId : ArchiveSHA256TreeHash : ArchiveSizeInBytes : 0 Completed : False CompletionDate : 01/01/0001 00:00:00 CreationDate : 06/04/2021 15:19:04 InventoryRetrievalParameters : Amazon.Glacier.Model.InventoryRetrievalJobDescription InventorySizeInBytes : 0 JobDescription : test inventory retriaval JobId : yyvnQ4O4hNLRpR5PQg3_UlKMSho3eII6bAKOc3X3vMK3UYE6yO_9IyxvR8UCkgO4_nShr6rUPPFg11ycRL262Lut48zl JobOutputPath : OutputLocation : RetrievalByteRange : SelectParameters : SHA256TreeHash : SNSTopic : StatusCode : InProgress StatusMessage : Tier : VaultARN : arn:aws:glacier:eu-north-1:281499635336:vaults/Photos
Suivre les job spécifiquement Get-GLCJob -JobId $jobid -VaultName Photos. Une fois celui-ci terminé, ça peut prendre un moment (quelques heures). Pour récupérer le résultat de votre inventaire, Il faudra utiliser la cmdlet :
Read-GLCJobOutput -JobId $jobid -VaultName Photos -FilePath "inventory-retriaval.txt"
Note : Bon ca on s’est fait chi… mais je voulais vous montrer comme en alpi si vous ne le faite pas vous même c’est pas le glacier qui le fera pour vous, mais aussi que rien n’est vraiment perdu dans un glacier : tout fini par ressortir.
En cas d’oubli simple comme ça arrive, pensez à la variable $AWSHistory qui enregistre les dernières requête et réponse faites via le module… Je rajoute au passage qu’il ne s’agit pas de Job PowerShell, si vous fermez la console et en rouvrez une autre vous retrouverez votre job.
Le script de bakcup
Bon voilà, enfin ! On y est on va pouvoir backuper notre dossier photos. Donc pour votre informations je stocke mes photos dans une arborescence de fichier comme ça.
- Photos (rootdir)
- 2009
- 2010
- 2010-01&02 -divers
- etc.
- 2011
- …
- 2020
- 2021
- 2021-01 – Noel et Nouvel An
- 2021-04-21 – Balades
A partir de là, on peut choisir d’exporter ça comme on le souhaite. Moi j’ai fait un seul Vault et une archive par dossier « feuille ». Mais on pourrait très bien faire un Vault par années. C’est vous qui voyez en fonction de vos besoins !
Du coup à la fin, mon petit script d’archivage ressemble à ça :
# Amazon Glacier photo dir Backup script
$sourcedir = 'Z:\Photos\'
$VaultName = 'Photos'
$AWStmpDir = Join-Path $sourcedir 'AWS'
$inventoryfile = 'inventory.csv'
$inventoryPath = Join-Path $AWStmpDir $inventoryfile
If(!(test-path $AWStmpDir)) {
New-Item -ItemType Directory -Force -Path $AWStmpDir
}
# lister les sous-dossiers du dossier racine
$subdir = Get-ChildItem $sourcedir
New-Item ($AWStmpDir+'\'+$inventory) -ItemType File
Set-Content -Path $inventoryPath -Value "VaultName,description,ArchiveId,zipname"
foreach ($dir in $subdir) {
# Lister les albums dans chaque sous-dossier.
$album_dirs = Get-ChildItem $dir.FullName
foreach ($album in $album_dirs){
# on conserve le chemin complet pour l'historique
$description = $album.FullName
$zipname = Join-Path $AWStmpDir ($dir.Name.Replace(' ','_')+"_"+$album.Name.Replace(' ','_')+".zip")
Compress-Archive -Path $dir.FullName -DestinationPath $zipname -CompressionLevel Optimal
#Envoie à AWS GLC
$result = Write-GLCArchive -VaultName "$VaultName" -File "$zipname" -Description "$description"
# On conserve précieusement l'archiveID
Set-Content -Path $inventoryPath -Value "$VaultName,$description,$($result.ArchiveId),$zipname"
# on dégage l'archive temporaire avant de passer au dossier suivant
Remove-Item -Path $zipname -Confirm:$true
}
}Récupérer les données
Bon c’est un service d’archivages, de long termes, clairement l’idée ce n’est pas de faire appel à la restauration toutes les 5 minutes. D’ailleurs la facturation est en partie basée la dessus. Donc clairement S3 Glacier c’est votre dernière carte en cas de sinistre. C’est mieux de savoir récupérer ces données avant de les avoirs mises qu’après quand même. Du coup pour récupérer vos une archives :
Start-GLCJob -VaultName Photos -JobType 'archive-retrieval' -ArchiveId "xEvQrscsP02rxlHW5hTsjCRzdr03Bj7-SY4ohdaA6u-8Kf_ilGqootfctJg523AkhEtdgSsnsZNhOpdEWwtkt2ZvGy__" -JobDescription "everything burned please get my data back ASAP !!!"
Comme pour l’inventaire, ça va vous faire un « Job » dont il faudra attendre qu’il se termine pour récupérer vos données avec :
Read-GLCJobOutput -VaultName Photos -JobId "csP0...sjCRzdr03" -FilePath "Z:\Photos\AWS\test.zip"Conclusion
Bon alors quoi conclure sur l’archivage avec Amazon S3 Glacier ? Alors déjà, que ce n’est pas « pour tout le monde », l’archivage avec Amazon S3 Glacier. Il y a pas mal de concepts à comprendre pour s’en servir correctement. Ensuite que niveau tarif, ça reste quand même très très compétitif. En particulier si vous avez peu de données à archiver (comme un particulier). Mais en sachant que la facture arrivera quand vous voudrez récupérer les données. Pour un service d’archivage auquel c’est plutôt pas logique. Quand votre maison a brûlée, vous n’êtes plus aux 30€ près pour récupérer vos 420Go de photos.
Si vous avez les jetons de donner tout ça à Amazon, rien ne vous empêche de chiffrer vos données avant de les envoyer (qui a dit Zed!)… Mais ne perdez pas la clé de chiffrement… 😉 Après à savoir que vous êtes lié avec Amazon, s’il décide de tripler leur tarifs en 2022 et que vous avez 25 Po de données chez eux : ça va piquer.
De mon côté je me suis bien marré à archiver tout ça. Pour l’instant ça fait le taf que je demande (si on pense bien à conserver précieusement l’inventaire des Archives ID). Et c’était plutôt intéressant de me pencher sur les services d’AWS que je ne connaissais pas trop pour le coup. Je les ai trouvés convainquant et je comprends que certains RSSI se fasse du souci au sujet de l’externalisation vers le Cloud dans leurs SI interne…
Bref, Voilà pour le petit article que je voulais vous écrire, au final j’ai fait un roman… Si ça peut en aider un ou deux à se mettre les crampons au pied pour aller monter sur un glacier, moi je suis content ! Grimpez bien !
