

Bonjour à tous, Il y quelques temps (environ :-)) on m’a demandé d’organiser un CTF en interne au taf. Je pourrais vous parler un moment du projet, des contributions au challenges, de l’organisation ou de la com’ mais bon, c’est pas trop le but du blog de vous parler des trucs chiant…^^ Je voulais juste pour partager quelques requêtes SQL et SPL pour CTFd et Splunk que j’ai faites en fin de CTF pour générer des graphiques et quelques stats sur le déroulement du challenge.
Alors je l’ai pas indiqué mais on a utilisé un CTFd customisé (un peu, merci Keny) pour l’occasion. Derrière la plateforme on trouve donc une base MariaDB (ex-mysql) tout bête qu’on peut requêter avec du SQL tout ce qu’il y a de plus classique.
SQL over CTFd
Par exemple la liste des utilisateurs inscrit au CTF vers un CSV :
Select u.id as user_id, u.name as username, u.email as user_email, u.type as user_type, u.team_id as team_id, t.name as team_name, captain_id, u.created as user_created INTO OUTFILE '/tmp/ctfd_users.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM users as u LEFT JOIN teams as t ON t.id=u.team_id ORDER BY team_name;
Ça vous sort un beau csv pour envoyé à vos équipes de com’ sur les participants…^^
Plus intéressant, la chronologie des soumissions des flags sur la plateforme.
SELECT s.date as submission_date, s.id as submission_id, s.challenge_id as challenge_id, c.name as challenge_name, c.value as challenge_point, c.category as challenge_category, s.user_id as userid, u.name as username, t.id as team_id, t.name as team_name, s.provided as flag, s.type as status INTO OUTFILE '/tmp/ctfd_submissions.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM submissions s JOIN teams t ON s.team_id=t.id JOIN users u ON s.user_id=u.id JOIN challenges c ON c.id=s.challenge_id ORDER by s.date;
Mais aussi la chronologie des déblocage d’indices :
select u.date as event_date, u.id as unlock_id, u.user_id as unlock_user, us.name as username, u.team_id as unlock_teamid, t.name as team_name, u.target as hint_id, h.challenge_id, h.cost as cost, u.type as unlock_type INTO OUTFILE '/tmp/ctfd_unlocks.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM unlocks u JOIN users us ON u.user_id=us.id JOIN teams t ON u.team_id=t.id JOIN hints h on u.target=h.id;
Normalement vous devriez me voir venir avec mon Splunk là… 🙂
Splunk
Alors j’ai pas fait un dasboard complet puisque la plateforme donne déjà quelques stats toute seule mais en injectant les fichier de submissions et unlocks dans un index on peut rapidement sortir les requêtes suivantes :
Le classement des teams (qu’on a déjà dans la plateforme ctfd, hein) :
index="ctfd" (source="ctfd_submissions.csv" status=correct) OR source="ctfd_unlocks.csv" | stats sum(challenge_point) as points sum(cost) as unlocks last(_time) as last_sub by team_name | fillnull value=0 unlocks | eval total=points-unlocks | sort -total +last_sub | convert ctime(last_sub) | table team_name total
Les équipes qui ont grillées le plus d’indice :
index="ctfd" source="ctfd_unlocks.csv" | stats count by team_name
Une basesearch des résolution de challenge par équipe :
index="ctfd" (source="ctfd_submissions.csv" status=correct) | table team_name challenge_name _time | sort team_name challenge_name _time | streamstats current=f last(_time) as previoustime by team_name | fillnull value=1615293000 previoustime | eval duration = _time - previoustime | convert ctime(previoustime)
Les temps les plus court de résolution par challenge :
index="ctfd" (source="ctfd_submissions.csv" status=correct) | table team_name challenge_name _time | sort team_name challenge_name _time | streamstats current=f last(_time) as previoustime by team_name | fillnull value=<TimeStampDebutCTF> previoustime | eval duration = _time - previoustime | convert ctime(previoustime) | sort challenge_name duration | stats first(team_name) first(challenge_name) first(duration) by challenge_name
L’inverse, les temps les plus long de résolution par challenge :
index="ctfd" (source="ctfd_submissions.csv" status=correct) | table team_name challenge_name _time | sort team_name challenge_name _time | streamstats current=f last(_time) as previoustime by team_name | fillnull value=<TimeStampDebutCTF> previoustime | eval duration = _time - previoustime | convert ctime(previoustime) | sort challenge_name duration | stats last(team_name) last(challenge_name) last(duration) by challenge_name
Les ratio de résolution par équipe :
index="ctfd" (source="ctfd_submissions.csv") | stats count(eval(status="correct")) as correct count(eval(status="incorrect")) as incorrect by team_name | eval total=correct+incorrect | eval ratio_correct=round(correct/total*100,2) | eval ratio_incorrect=round(incorrect/total*100,2)
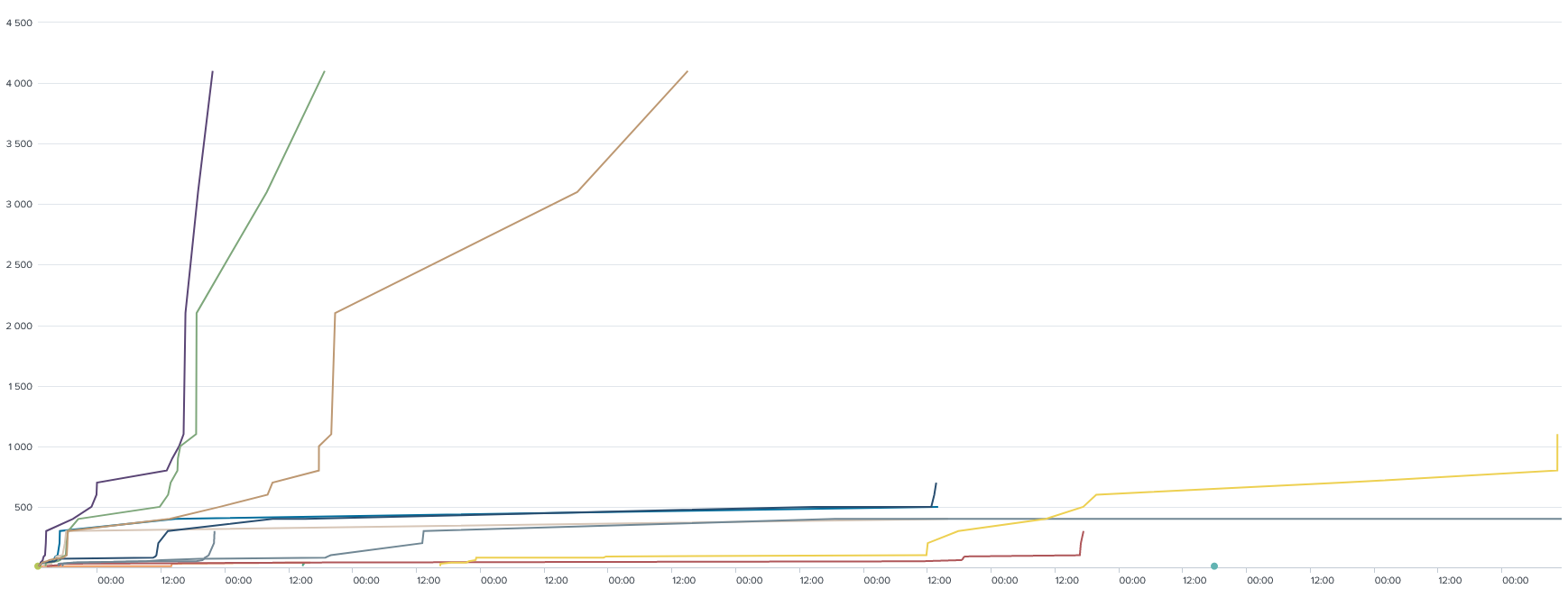
Et le Timechart des scores ;
index="ctfd" (source="ctfd_submissions.csv" status=correct) OR source="ctfd_unlocks.csv"
| table team_name challenge_name challenge_point cost _time
| sort _time
| streamstats current=t sum(challenge_point) as score sum(cost) as unlocks by team_name
| xyseries _time team_name score
Qui vous fera un jolie graphique comme ça :
CTFd et Splunk
Voilà, c’est tout pour cet usage de CTFd et Splunk : si ca peut reservir à quelqu’un ! Je pense que je vous repartegerez un des challenges que j’ai fait dans le cadre de ce CTF à base de RC4, PowerShell et de DB chiffrées, et sur lequel certains participants se sont bien pris la tête amusés ! Voilà c’est tout, Geekez-bien !
