
Bonjour à tous, aujourd’hui on termine avec ce tutoriel QRadar AQL le cycle sur le SIEM d’IBM. Dans les précédents tutos, on a vu le fonctionnement du langage de requêtes de QRadar : l’AQL, puis comment ce dernier interagit avec les différents composant de Qradar notamment via les mécanismes d’indexation, dans le but d’optimiser nos requêtes. Pour finir cette série, on va s’attarder sur les dernier gros éléments de logiciel : les offenses, rules et building block ; ainsi que les Reference data, l’API et les visualisations.
AQL : Advanced Quombat Langage ?
Les offenses

On va commencer ce tutoriel QRadar AQL en parlant dece qu’est une offense : c’est un incident qui est généré dès que les conditions d’une règle sont réunies. Dans le logiciel, l’importance d’une offense est caractérisée par sa magnitude. Une magnitude : comme pour les séismes, elle est basée sur ces trois paramètres :
- Relevance : c’est la surface d’exposition ;
- Credibility : taux de faux positif ; et
- Severity : est-ce grave ou non.
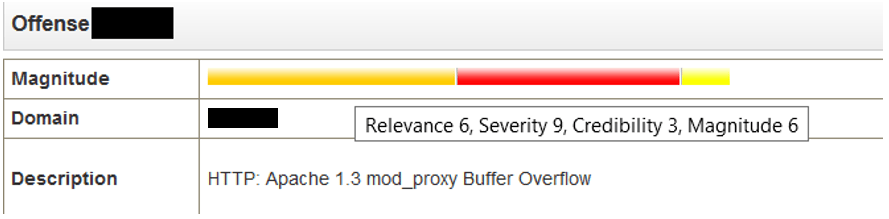
Notez que c’est l’implémentation technique de l’offense qui alimente ces éléments, il faut donc faire attention à ne pas prendre leur valeur pour comptant car ce n’est pas nécessairement fait correctement selon les infra.
Offense index field
Une spécificité d’IBM sur son système d’offense, c’est que le système ne créé pas d’incidents « isolés » qui seront levé à chaque détection. Dans l’interface, les offenses sont regroupées via un « champs index » (par exemple, l’IP ou le nom d’utilisateur). Cela signifie que si une autre règle doit lever une offense qui a un champs d’index avec la même valeur, cet évènement sera rattaché à l’offense déjà ouverte (et ce, même si les deux alertes n’ont pas de lien au final). Notez au passage que le champs d’index dont on parle correspondent aux champs standard ou custom properties qu’on a évoqués dans le TP précédent.
C’est dans la définition des règles que l’ont choisi sur quels champs se fait le rattachement. Le choix de ce champ est critique dans la configuration d’une offense car il conditionne la création de l’offense (et s’il est absent rien n’est créé d’ailleurs), en gros vous devez le voir comme la clé primaire de vos offenses.
Rules, building block, évaluation ?
Les offenses sont levées par des « rules » qui sont-elles même constituées, entre autre, de « building block ». Une particularité de QRadar (notamment par rapport à un Splunk), c’est que les règles qui génèrent les offenses sont évaluées à chaque évènement lorsqu’il est intégré dans l’infrastructure.
Cela engendre quelques points importants :
- Déjà le système est de type « temps réel », les offenses sont évaluées à l’arrivée des évènements. Et non pas lors de recherches planifiées régulièrement sur les logs arrivés dans la dernière période.
- Cela signifie que chaque règle ou building block rajoutés vont potentiellement (si les règles sont mal conçues) s’appliquer à tous les évènements qui arrivent. Même si le système implémente la « lazy evaluation » sur ces règles, il reste nécessaire lors de leur conception de réfléchir à l’impact sur les performances de ces règles (cf. TP n°2).
- Seconde conséquence du 1er point, on ne peut pas écrire les règles en AQL directement, mais il est quand même possible d’inclure de l’AQL dans leur définition.
Conceptuellement, une règle : c’est un test logique, comme un IF en programmation, qui s’appliquera à chaque évènement qui rentre dans le système. Ce IF est composé de différents « test group » liés par des OR ou AND. Ces test group peuvent être prédéfinis dans Qradar, par exemple : le log source group est parmi ceux du firewall ; ou personnalisé : grâce aux building block.
Building block
Un building block est défini comme une règle à la différence qu’il ne génère pas d’offense ou d’action personnalisée mais retourne simplement vrai ou faux pour être intégrer dans les test group d’une ou plusieurs règles.
Ils sont par exemple prévus pour tester les même groupes d’hôtes de votre réseau dans plusieurs offenses et partager ces définitions dans un seul building block entre toutes les alertes. On peut aussi les utiliser comme des TAG à placer sur les évènements. Ou encore simplement quand on veut séparer une règles complexe en plusieurs éléments plus simple.
Définir une nouvelle offense

Qradar inclus un ensemble de règles et offenses préexistant mais il bien évident possible d’en définir d’autres. Pour cela dans le menu « offense » sur l’interface : allez dans Rules, puis Actions-> New rules. La seconde fenêtre de l’assistant permet de choisir sur quoi les règles de l’offenses s’applique.
Dans la fenêtre suivante, dans apply on nomme la règle. Il faut choisir si celle-ci est appliquée en local (sur l’event processor qui gère les log), ou en global c’est-à-dire que tous les logs qui matchent sont envoyés vers la console centrale qui s’occupera de faire la corrélation. Le choix entre local et global dépend énormément de l’infra, du nombre de processor présent, de la manière dont vos logs arrivent dans les collecteurs (répartis entre les collecteurs notamment). Le risque à passer en local c’est manquer des events qui arriverai sur d’autres collecteurs, par contre les passer en global c’est augmenter les ressources nécessaires au à leur analyse sur la console.
Une fois la règle nommée, vous sélectionnez ensuite dans les « tests group » (ou règles) qui doivent matcher pour générer une offense. C’est à ce moment que vous pouvez transformer votre règle en building block ou inclure des building block comme base de vos règles. Avant de terminer, il faut appliquer les groupes d’offenses qui correspondent à votre offense. Cela peut être groupe associé à l’organisation (Département/service/entité/filiale/etc.) ou des catégories de règles défini dans le catalogue.

Action et réponse à l’offense
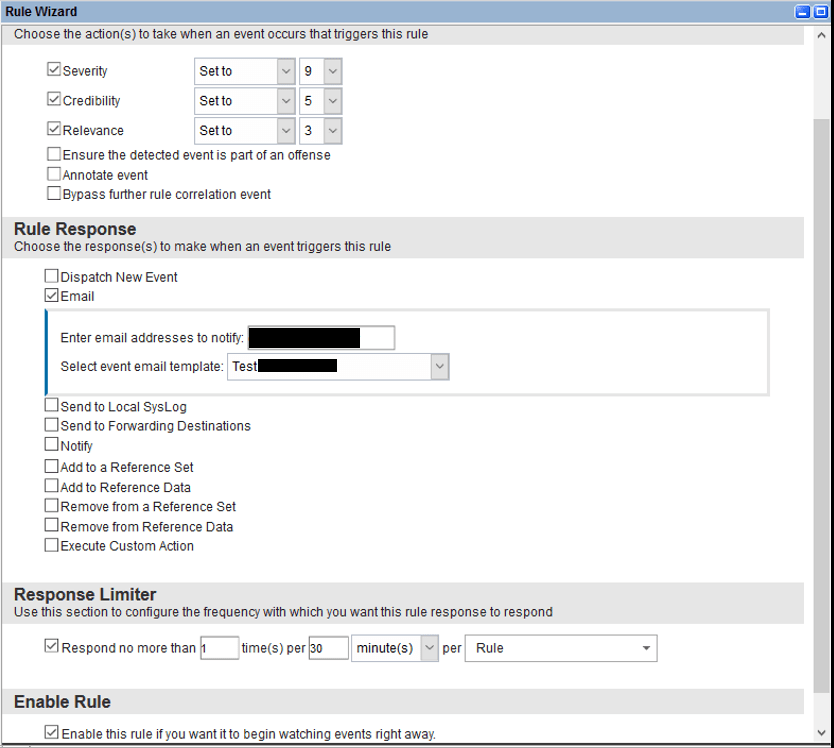
La fenêtre suivante vous permet de choisir quelles actions lancer quand votre règle matche. La première partie concerne uniquement la création de l’offense. Mais il est possible d’avoir d’autre actions programmées : mail, log interne ou externe, ajout à une base de connaissance interne Qradar.
Le fait de générer un log à l’ouverture d’une offense est très utile il cela permet de d’avoir plusieurs niveau d’alerting qui ne déclenche sur toutes les alertes mais qui peuvent alimenter des meta-déclencheur (par exemple sur une somme de sévérité-relevance-crédibilité/by username/period) voir des algorithmes de machine Learning ou d’IA.
Si vous allez jusqu’au bout de l’exercice de création : vous aurez un récapitulatif et c’est fini. Vous pouvez alors retrouver votre offense dans le menu all offense et utiliser la recherche pour filtrer les offenses qui vous intéresse.
Reference data
A ce stade du tutoriel QRadar AQL, vous devriez être à peu près autonome sur vos recherche AQL dans Qradar et créer vos offenses, mais aussi sur la découverte des logs que sur le filtrage de ceux qui vous intéresse. Avant de finir, il nous reste à voir comment étendre ces résultats « techniques » avec des informations « métier ». Par exemple, convertir un NNI en un nom d’utilisateur, ou une IP en nom de domaine ou n° de poste. Chez Splunk ils appellent ça des lookup et en gros, c’est CSV pour compléter vos données avec des informations non-évènementielles (inventaire, annuaire LDAP, DNS, etc.).
Qradar est un peu beaucoup plus (trop ?) limité que Splunk sur ce sujet car il fixe arbitrairement le nombre de colonnes de ce qui l’appelle les références data collections. Il en existe différents types :
- Set : collection de valeur unique, genre tous les logins existant à EDF et on peut tester un UserName est présent ou pas dans cette liste.
| data |
- Map : correspondance entre une valeur unique genre un username avec une valeur supplémentaire : genre son nom Prénom et unité.
| key1,data key1,value1 key2,value2 |
- map of set : même chose qu’une map mais pour plusieurs valeurs supplémentaires via des set. 192.168.1.8 -> {Adam, Daniel, Rafal}, par exemple pour l’appartenance à un group.
| key1,data key1,value1 key1,value2 |
- map of map : même chose qu’une map of set, mais elle fait correspondre avec un élément supplémentaire de type clé qui permet de mappé sur un autre map ou set par exemple :
| key1,key2,data map1,key1,value1 map1,key2,value2 |
- reference table : même chose qu’une map of maps mais la seconde clé à un type assigné :IP/CIRD par exemple.
| key1,key2_datatype,data map1,cidr1,value1 map1,cidr2,value2 |
Notez que vous pouvez gérer ces tables existantes via l’API REST tout comme dans l’interface sous Admin-> Reference Set Management. Ce qui fait une transition tout trouver vers la suite.
QRadar REST API
Comme beaucoup de solution récentes, Qradar propose une API REST dont vous trouverez la documentation ici. La bonne nouvelle c’est qu’on peut se servir de cette API pour afficher des rapports avec le module Pulse (ou dans un Splunk free si vous ne voulez pas vour faire trop mal…). Je ne vais pas m’attardez plus dessus, d’autant plus que pour maquetter vos requêtes vers l’API avec le module interactif directement dans l’interface de Qradar est pas si mal foutu que ça.
Afficher des graphiques – Pulse et report

C’est bien tout ça, mais comment fairre un Tutoriel QRadar AQL sans parler de dashboarding quand on voit la concurrence avec Splunk. On encore pas vu comment on pouvait sortir nos données autrement que dans une CSV ou un XML, c’est un peu léger… C’est là que le module PULSE intervient, celui-ci est prévu pour afficher les données. Ce dernier est « particulier ? » à utiliser, notamment pour les times series (doc et doc), mais il permet quand même de sortir de genre de graphique.
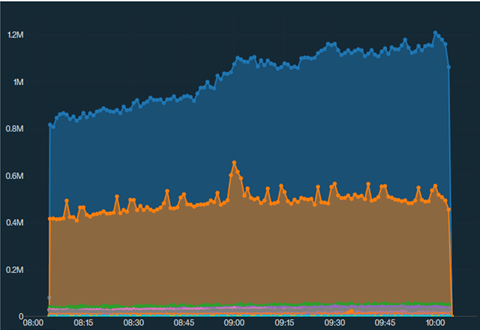
Ce graphique est construit via une requête AQL dans le module pulse. Cette requête est un peu étrange au premier abord, car elle nécessite de segmenter manuellement dans la requête les intervalles de temps (en jaune ci-dessous)
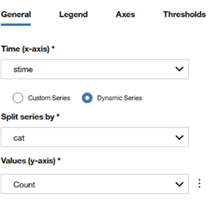
SELECT starttime/(1000*60) as minute, DATEFORMAT(starttime,'YYYY MM dd HH:mm:ss') as showTime, MIN(starttime) as stime, CATEGORYNAME(category) as cat, SUM(eventcount) as "Count" FROM events WHERE "logsourceid"='1234' GROUP by minute, cat ORDER by minute ASC last 2 HOUR
Le module Pulse permet aussi de générer d’autre type d’affichage : camembert, carte, pourcentage, graphique, « bar-chart ». Il suffit de reprendre un exemple existant pour voir le format de la requête attendu en entrée et adapter votre requête pour un affichage dans Pulse.
QRadar supporte aussi un module de reporting plus traditionnelle permettant l’envoi de rapport planifiés. C’est l’onglet Report dans l’interface fait cette fonction. La grosse différence entre Pulse et Report, c’est le mode de construction. Pulse génère le rapport à la demande, alors que le module report construit le rapport au fur et à mesure de la réception des évènements grâce à des accumulateurs (réf) qui compte les évènements souhaités dès leur arrivée. Beaucoup plus efficace à l’affichage comme le rapport est déjà prêt lors de la demande, ils l’ont l’inconvénient de consommer des ressources à l’infrastructure pour les maintenir à jour en permanence. Et donc… d’être limité en nombre selon des préconisations de l’éditeur à quelques centaines dans une infra, en plus de ne pas traiter directement la donnée, ce qui limite également la capacité à creuser les logs en cas de d’incohérence.
Conclusion
Bon voilà, on est au bout de cette série de Tutoriel QRadar AQL. On n’a inévitablement pas tout vu de Qradar. Je vous laisse explorer par vous-même ces éléments notamment : les SESSION en AQL pour remonter des séquences d’évènements ou encore détailler les source type existant, l’optimisation des expressions régulières ou les plugins de l’éditeurs. Mais, à ce stade, vous avez désormais toutes les bases pour travailler avec QRadar sans effondrer l’infrastructure et comprendre les documentations de l’éditeur et vous auto-former sur la solution. J’espère que ça vous aura intéressé, moi j’ai trouvé que ça manquait beaucoup ce genre de contenu pour se mettre le pied à l’étrier en arrvivant, du coup je suis content d’avoir pu vous repartager mon Tutoriel QRadar AQL ici.
De plus, même si mon constat personnel sur QRadar reste très mitigé, ils y a malgré tout quelques bonnes idées à piquer dans le produit et… à réimplémenter dans Splunk 🙂 ! Vous n’êtes pas d’accord ? je suis ouvert au débat (mais trop…^^). Bref, Geekez-bien et à la prochaine !!!
