
Bonjour à tous, aujourd’hui on continue le tutoriel QRadar AQL commencé la semaine dernière. Dans le précédent TP, on avait vu les principales notions du langage de requête de QRADAR, l’AQL (Ariel Query Langage). Cette fois on va se concentrer sur l’utilisation de ce langage dans l’infrastructure QRadar et tous les petits raffinements qui lui sont associés. Mais d’abord et dans ce Tutoriel QRadar AQL on va devoir s’intéresser au fonctionnement d’une infrastructure QRadar
Je l’indique de nouveau ce post c’est du « vrai taf » ça, du coup je profite de cette introduction pour remercier mon équipe à EDF qui m’autorise à republier ce travail… On lâche un pouce bleu pour EDF c’est pas systématique les boites sympas qui autorisent ça 🙂 ! The SOC needs you, tout ça tout ça, hein… :-).
AQL : Advanced Questions Level ?
Dans le précédent Tutoriel QRadar AQL, on avait vu les principales notions du langage de requête de QRADAR, l’AQL (Ariel Query Langage). Cette fois on va se concentrer sur l’utilisation de ce langage dans une infrastructure QRadar et tous les petits raffinements qui lui sont associés. Mais d’abord, on va devoir s’intéresser au fonctionnement d’une infra QRadar.
Un peu de vocabulaire
Dans Qradar quand on parle de :
Générateur de log :
C’est une source qui génère des logs, via : Syslog, API, JDBC, UDP, fichier, etc. Dans le collecteur ci-dessous, ces éléments seront identifiés comme des « Log source ».
Collecteur :
C’est ici que les log émis par les log source sont réceptionnés, que le système vérifie que le nombre d’évènements par seconde ne dépasse pas la licence et que les champs par défaut sont parsés (interprétation du contenu via des regex). Quand un log arrive, c’est l’IP ou le hostname de la source dans le syslog qui définit le sourcetype. Ensuite 2 champs importants sont extraits : l’EventID et l’EventCategory. Ces 2 éléments génèrent un EventName (QID en interne). Ce QID est important ça s’est lui qui définit les Low Level Category et High Level Category et qui permet d’appliquer un DSM (voir plus bas) différent selon le type d’évènement (i.e. le format du log.)

C’est ce QID (avec le log source type, la category et le log source) qui va participer à définir les champs « custom » à extraire (via le DSM) en plus des champs standard pour ce log source type. Les champs extraits se séparent en 2 catégories, les « standard » et les « custom properties » : Les champs par défaut sont ceux qui ne sont pas marqués comme « custom » dans l’interface et ceux présent sont automatiquement stockés en plus du « payload » dans Qradar :
- Event Name
- Low Level Category
- Event Description
- Magnitude
- Relevance
- Severity
- Credibility
- Username
- Start Time
- Storage Time
- Log Source Time
- Source and Destination information
- Source IP
- Destination IP
- Source Asset Name
- Destination Asset Name
- Source Port
- Destination Port
- Pre NAT Source IP
- Pre NAT Destination IP
- Pre NAT Source Port
- Pre NAT Destination Port
- Post NAT Source IP
- Post NAT Destination IP
- Post NAT Source Port
- Post NAT Destination Port
- Post NAT Source Port
- Post NAT Destination Port
- Source IPv6
- Destination IPv6
- Source MAC
- Destination MAC
- Payload
- Protocol
- QID
- Log Source
- Event Count
- Custom Rules
- Custom Rules Partially Matched
- Annotations
- Identity Username
- Identity IP
- Identity Net Bios Name
- Has Identity (Flag)
- Identity Host Name
- Identity MAC
- Identity Group Name
Comme je le disais, en plus de ces champs par défaut, selon le type de logs, un « DSM custom » peut être appliqué. DSM c’est pour : « Device Support Module ». C’est le module du collecteur qui gère les events qui arrivent pour les parser dans Qradar et qui va étendre les champs existants. 2 options pour ce DSM :
- Soit il s’agit d’un source type supporté nativement par Qradar et pour lequel il existe une entrée dans le DSM Configuration Guide.
- Soit il n’y est pas, et on doit définir ce qu’on veut extraire manuellement, via le DSM editor ou un LSX.
Ce DSM peut définir des custom properties (en plus des champs standard de QRadar), ces dernières sont définies par des expressions régulières et peuvent être dans 2 cas, stockés ou non stockés. Ce choix est fait lors de la création de la CUSTOM propertie en cochant ou non la case « Enable this Property for use in Rules and Search Indexing »:
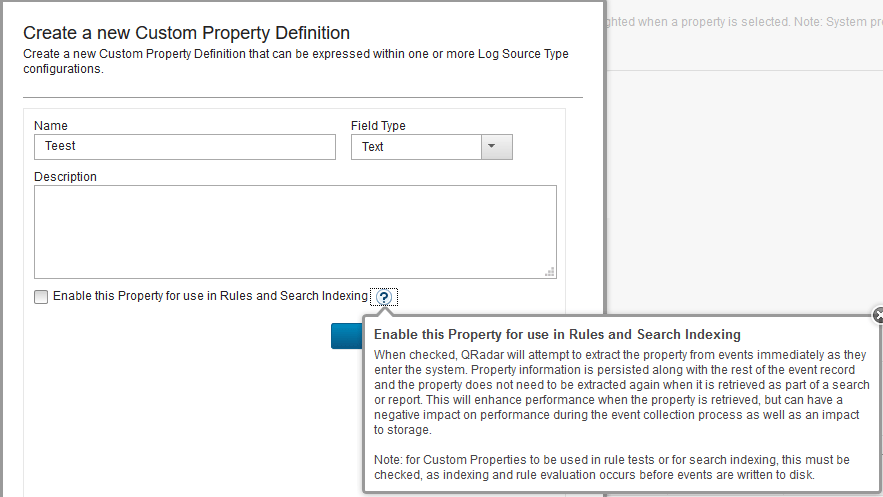
Dans le cas où cette case est cochée : le Qradar effectuera une extraction de ces champs dès la réception du log et stockera ce champ en plus du payload et des champs standards. Cela augmente de facto l’espace nécessaire au stockage au prorata de la taille du champ extrait.
Dans le cas où cette case n’est pas cochée : Qradar n’appliquera la regex que lors de la recherche pour extraire le champ, ce qui empêche de l’utiliser dans les offenses et les indexs.
La création des « custom properties » est donc une opération technique qui ne doit pas être prise à la légère dans la mesure où leur nombre et stockage impactent directement les performances de l’infra et de la recherche en augmentant le volume de log à parcourir lors des recherches non-indexées.
Le Processeur de log
C’est lui qui est responsable du stockage et de l’indexation des logs, de la réalisation des recherches. C’est également lui qui va extraire les CUSTOM properties via des expressions régulières dans le DSM editor lors de la recherche quand elles ne sont pas stockées, ce qui permet de rajouter des informations sur les logs.
Console
C’est la partie émergée de l’iceberg qui fait office d’IHM et gère également le processus d’offenses et effectue des demandes de recherches auprès des processeurs de log.
Comparaison ELK et Splunk
Je trouvait qu’il était dommage de faire un Tutoriel QRadar AQL et de ne pas parler de la concurence. On notera donc ici que dans le fonctionnement ce modèle est très proche d’une Stack ELK au final, avec une extraction de champs à la réception des logs (logstash), un stockage étendu avec les champs extraits (MongoDB/ElasticSearch) et pas lors de la recherche. Et donc à l’inverse d’un Splunk ou l’extraction de champs est faite en grande majorité lors de la recherche et où seul les champs nécessaires (par défaut 3, mais personnalisable) à la construction des index sont extraits à la réception des logs. On notera quand même que les Datamodel dans Splunk permettent d’obtenir le même comportement d’indexation de plus de champs à la reception (contre du stockage comme pour ELK et QRadar du coup).
L’indexation :
Quand un évènement arrive dans l’infrastructure, on a vu que celui-ci est traité par Qradar et que certains éléments (champs) sont mis de côté, pour être indexé avec le payload de l’évènement. Les champs indexés sont évidemment beaucoup, beaucoup, plus rapides à interroger lors des recherches. On peut voir quels champs sont indexés lorsqu’on clique sur « Add-filter » dans l’interface de recherche. Voici un récapitulatif, au moment de la rédaction de ces lignes, des champs indexés par défaut. Notez que cette liste peut être entièrement personnalisée et ne correspond donc pas forcément à vos implémentation locale.
- Custom Rule
- Custom Rule Partially Matched
- Destination IP
- Destination Port
- Event Name
- Has Identity
- Log Source
- Log Source Type
- Low Level Category
- Source IP
- Username
En l’absence de notion d' »index » comme dans Splunk ou ELK, une bonne règle est donc de commencer ses recherches sur des champs indexés, puis à raffiner si besoin sur les autres champs. Il ne faut donc pas être « trop spécifique » immédiatement au risque de nuire aux performances de sa recherche.
- Le choix des champs indexés est critique pour les admin Qradar et pour les recherches.
- Lors de l’ajout de type de log, l’intégration doit chercher à réutiliser des noms de champs déjà indexés pour avoir un modèle homogène.
- Il faut revoir régulièrement (fonction de l’infra) les champs indexés pour matcher aux besoins des recherches.
Le quick filter
C’est un peu con de ma part de ne pas avoir commencé par là mais bon, il y a marqué Tutoriel QRadar AQL, pas Tutoriel QRadar Quick Filter hein…. Bref Si vous tapez en dehors des données indexées dans une recherche, Qradar re-parcourra toutes les données. Ce mécanisme se fait en constuisant des « Payload Index » ce qui fait reconstruire à Qradar un index temporaire pour la période de temps demandé (en bref, c’est un cache quoi). Par défaut ces « Payload index » sont conservées 30j. Les recherches en quick filter devraient donc privilégier également les champs indexés pour éviter de polluer l’infra de Payload Index.
Quelques règles d’optimisation facile :
Rapidement, voici quelques best-practice de construction de vos recherches :

- Ajuster la timeframe : Comme dans un Splunk, Qradar range les données temporellement en plus des index, plus vous êtes spécifique sur votre timeframe, plus elle est réduite, moins il aura de données à parser plus ça ira vite ! La règle est presque linéaire (si on exclut la compression des données et l’expiration des index). Travaillez toujours sur une période de temps limité avant de passer à une période ouverte.
- Utiliser le mot clé Limit : dans un premier temps quand vous construisez une recherche limitez-vous au 1000 premiers résultats et supprimer le LIMIT à la fin de vos requêtes AQL. Vos itérations iront plus vite et vous éviterez de saturer l’infra Qradar au passage. Retirez le LIMIT quand votre recherche est prête à être lancée sur toutes les données.
- Evitez « Select * » : et spécifier les champs que vous voulez récupérer en effet ce faisant vous limitez la quantité de données à charger en mémoire et donc la vitesse de votre recherche et la charge de l’infra.
- Soyez progressif : lorsque vous cherchez sur une période de temps importante, il est pertinent de préparer d’abord votre requête sur une période restreinte (genre les 7 derniers jours). Cela permet d’optimiser votre requête avant de la faire tourner sur toutes les données. Cela permet aussi de valider l’existence de résultats récents, qui pourrait modifier la recherches (genre découverte d’un autre Ioc dans un champ qui serait indexé \o./) qui feront que votre recherche sur 6 mois terminera au final plus rapidement que celle sur la semaine.
Le double effet sympa d’élargir progressivement, c’est que QRadar conservera l’historique de vos recherches en cache, élargira la période de recherche, et réutilisera des résultats déjà trouvés. Ce qui vous permet d’itérer sur vos recherches. - Utilisez les champs indexés en priorité : Les recherches filtrant sur ces champs seront beaucoup plus rapides.
- Faites des subquery : les subquery vous permettent de découper finement vos recherches et surtout l’ordre dans lequel les filtres vont s’exécuter. Vous permettant de prioriser les champs indexés avant les opérations demandant plus de temps.
- Si vous connaissez l’event processor qui traite les données que vous cherchez, spécifiez-le comme filtre, ce qui permettra de ne pas interroger les appliances qui ne détiennent pas les données.
Un petit exemple
Cherchons les évènements contenant un texte arbitraire, par exemple le nom d’un site, sur une semaine. La recherche ci-dessous n’utilise pas de champs indexés et nécessite un peu plus de 10min pour s’exécuter.
SELECT * FROM events
WHERE TEXT SEARCH 'geekeries.org'
START '2020-01-13 00:00:00'
STOP '2020-01-20 23:59:59'
La même recherche avec un filtre supplémentaire sur l’adresse IP ne prend plus que 4min environ.
SELECT * FROM events
WHERE TEXT SEARCH 'geekeries.org' AND destinationip = '51.15.9.16'
START '2020-01-13 00:00:00'
STOP '2020-01-20 23:59:59'
Digression : Payload : afficher les évènements d’origine et customiser l’affichage.
Dans le cas où l’on a besoin de travailler avec les évènements d’origines et pas seulement avec les champs extraits par QRadar. Il est possible d’utiliser le champ PAYLOAD ainsi :
SELECT DATEFORMAT(starttime,'yyyy-MM-dd hh:mm:ss') as _time, sourceip,LOGSOURCENAME(logsourceid) as logsourcestr, eventcount,destinationip, destinationport, CATEGORYNAME(category) as category_name, QIDDESCRIPTION(QID) as event_name, UPPER(username) as username, severity, UTF8(payload) as _raw FROM events WHERE destinationip = '51.15.9.16' START '2020-01-13 00:00:00' STOP '2020-01-20 23:59:59'
Vous pouvez ensuite travailler ces champs comme un champ texte classique comme on le voit dans la suite de l’exemple ci-dessous.
Un petit exemple, la suite…
Par contre la dernière recherche construit intelligemment avec une subsearch a pris moins de 10ms
SELECT * FROM
(SELECT *,
UTF8(payload) as _raw
FROM events
WHERE destinationip = '51.15.9.16'
START '2020-01-13 00:00:00'
STOP '2020-01-20 23:59:59')
WHERE _raw MATCHES '.*geekeries.org.*'
On va terminer cet exemple avec ce qu’il ne faut surtout pas faire :
SELECT * FROM
(SELECT *,
UTF8(payload) as _raw
FROM events
WHERE _raw
MATCHES '.*geekeries.org.*'
START '2020-01-13 00:00:00'
STOP '2020-01-20 23:59:59')
WHERE destinationip = '51.15.9.16'
Cette recherche n’avait pas terminé de parcourir 1% des logs en plus de 5min… La manière dont vous écrivez vos requêtes a un impact très important sur la vitesse de celles-ci et la charge de l’infrastructure. De la même manière que l’extraction des champs est faite et couvre un maximum de format de log sur l’ensemble des format existants.
Tuer ses recherches qui ne terminent pas

Dans le cas où vous auriez quand même loupé votre optimisation sur une recherche, qui prendrait alors un temps non-NP important à terminer. Vous devez toujours allez la tuer manuellement (Qradar ne le fera pas pour vous, au risque de flinguer l’infra si tout le monde fait ça hein) en allant dans :
Puis en cherchant sur votre login, et sur Searches in Progress :

Vous pouvez alors tuer la recherche via un simple bouton-droit sur la ligne de recherche Cancel :
INTO CURSOR
On va continuer ce tutoriel QRadar AQL en parlant des recherches que l’on veut partager. Les curseurs sont un moyen de sauvegarder vos recherches et de les partager entre utilisateurs. Ils sont sauvegardés 5 jours par défaut et peuvent être utilisés ainsi.
Sauvegarde d’une recherche dans un curseur.
SELECT * FROM (SELECT *, UTF8(payload) as _raw FROM events WHERE destinationip = '51.15.9.16' START '2020-01-13 00:00:00' STOP '2020-01-20 23:59:59') INTO ETIENNE_AQL102_CURSOR WHERE _raw MATCHES '.*geekeries.org.*'
Et la récupération des mêmes résultats dans une autre recherche se fait ainsi :
SELECT * FROM ETIENNE_AQL102_CURSOR
Ces curseurs permettent notamment de ne charger qu’une fois un gros volume de données en cache lorsque plusieurs utilisateurs recherche dans le même ensemble.
QRadar ne permettant pas de travailler directement sur le contenu de plusieurs lignes de logs (comprendre extraire des champs supplémentaires), hors éditeur DSM, il est parfois utile de pouvoir exporter ses logs en CSV, XML, etc. pour le retravailler dans un Splunk Excel, ou simplement les exporter dans un cadre d’investigation et de collecte de preuve par exemple.
Pour cela, vous pouvez vous rendre dans Actions > Export to CSV > [Visible Colums | Full Export]

En cliquant sur Export le pop-up suivant va s’afficher :
Si vous cliquez sur « Notify When Done » vous recevrez les logs par mail (oui oui en P.J… attention si c’est un gros volume…). Mais si vous attendez, le téléchargement va être proposé en direct sur la page Web.
Conclusion
Voilà pour ce second Tutoriel QRadar AQL, à ce stade on commence quand même à y voir plus clair sur AQL et Qradar. Mais on pourra aller plus loin notamment en discutant sur la construction des champs custom et dériver sur la construction des expressions régulière, ou encore en parlant des « references data » et de la construction et gestion des offenses qui sont prévue pour le 3ème TP.

Bonjour,
Merci de m’assister pour comprendre comment en peux faire une recherche sur plusieurs adresse IP avec AQL
Hello Taha, merci pour ta question.
Contrairement à ce que cette série d’article peut laisser penser, je ne suis absolument pas expert en AQL (et j’en ai pas fait depuis 3 ans aussi). De mémoire, je crois qu’ils faut utiliser les references data dont je parle dans l’article suivant :
https://geekeries.org/2021/03/tutoriel-qradar-aql-advanced-search-103/
Toujours de mémoire, je crois que c’était surtout une question de combien,
– 2-3 IP : fait une recherche AQL à la mano avec des OR
– 20-30 : ca se chargeait pas trop mal à la main.
-200 et plus : il faut jouer avec l’API et il me semble que c’était faisable mais pas immédiat.
Dit nous comment tu t’en sera