

Marre des Captchas à noix ? aucun problème aujourd’hui on va résoudre ça grâce à la reconnaissance de caractères. Ça va se traduire sous forme d’une un gros TP pour debian (8.2 Jessie) où on va s’intéresser particulièrement au logiciel TESSERACT-OCR (OCR pour Optical Character Recognition).
Note : Tesseract-OCR n’a absolument rien à voir avec le tesseract des Avengers ou du film Cube, comme ça s’est dit…
Pour la petite histoire, il s’agit d’un logiciel initialement développé par HP (entre 1985 et 1995) puis abandonné. En 2005 le code source est finalement libéré sous licence Apache, et maintenu depuis par des équipe de Google. Tesseract-OCR est LA référence dans les moteurs de reconnaissance de caractères, il reconnait 60 langues au moment de la rédaction de cet article, à le bon gout d’être opensource et est déjà packagé sous la plupart des grosse distribution Linux : ce qui fait qu’il est utilisable quasiment clé en main sans trop se poser de question.
Sans transition, le github du projet : https://github.com/tesseract-ocr
(et l’ancien site sur Google Code : https://code.google.com/p/tesseract-ocr/)
Installation de TESSERACT-OCR
Pour les barbus, compilation depuis les sources
Avant de pouvoir installer Tesseract, il faut déployer un autre soft en prérequis.
Leptonica
Leptonica est un logiciel open-source de traitement et d’analyse d’image donnant accès aux fonctions suivantes (entre autres) :
- Transformation Affine (mise à l’échelle, translation, rotation, etc) ;
- Passage en noir et blanc, niveau de gris, ou encore convolution ;
- Combinaison de différentes transformations.
Et un gros paquet d’autres opérations mieux détaillées ici.
Vous pouvez commencer par télécharger les sources de leptonica ici. Ce qui donne dans un wget :
~# wget www.leptonica.com/source/leptonica-1.72.tar.gz
On extrait ensuite le .tgz comme d’habitude :
~# tar -xvf leptonica-1.72.tar.gz
Il suffit enfin de suivre la procédure d’installation sur le site officiel.
~# cd leptonica-1.72/ ./configure make make install cd ..
Et c’est bon… Sauf que par défaut, Leptonica ne supporte pas beaucoup de format d’image et si souhaite exploiter les formats d’images « courants » sur internet, il vaut bien avoir installé avant la compilation les bibliothèques suivantes :
- libjpeg ;
- libtiff ;
- libpng ;
- libz ;
- giflib ;
soit sous debian :
~# apt-get install libjpeg-dev libtiff-tools libpng++-dev zlib1g-dev libgif-dev
La commande « make check » vous permettra de vérifier la bonne présence de ces libs.Et oui, si vous aviez copier/coller/exécuter comme des bourrins toutes les commandes au dessus avant d’arriver ici vous pouvez recommencer cette partie. Ça vous apprendra à pas lire la doc jusqu’au bout avant de commencer !
Tesseract
Concernant Tesseract lui même la doc du soft est très bien faite, aussi je vous invite à la lire, car je n’ai fait que reprendre ce qui y est dit. C’est à dire :
Récupérer les sources :
~# wget https://github.com/tesseract-ocr/tesseract/archive/master.zip ~# unzip master.zip cd tesseract-master/
Pensez au passage, si besoin, à installer quelques outils nécessaires à la compilation :
~# apt-get install automake build-essential libtoolOn compile et on installe :
~#./autogen.sh~#./configure ~# make ~# make ~# install ~# ldconfig
Et c’est presque bon. En fait à ce moment tesseract est installé, mais la reconnaissance de caractères ne connait aucune langue (car elle se base aussi sur les digramme/trigramme probable dans une langue), il faut donc lui donner quelques données d’entrainements en entrée pour qu’il comprenne ce qu’on va lui donner.
Bref, intégrer les données d’apprentissages :
~# wget https://github.com/tesseract-ocr/tessdata/archive/master.zip
~# unzip master.zip
~# cp tessdata-master/fra.traineddata /usr/local/share/tessdata/ #français
~# cp tessdata-master/eng.traineddata /usr/local/share/tessdata/ #anglais
~# cp tessdata-master/lat.traineddata /usr/local/share/tessdata/ #latinou plus simplement si vous voulez tout copier :
~# cp tessdata-master/*.traineddata /usr/local/share/tessdata/Et voilà, vous devriez avoir la commande tesseract disponnible dans votre Shell à ce moment.
La méthode des faibles
Et donc vous pouviez aussi tout faire ça sur votre Debian 8.2 préféré, en tapant simplement :
~# apt-get install tesseract-ocr
Sans avoir à réfléchir plus que ça, mais ça aurait été beaucoup moins drôle, n’est-ce pas ?
Reconnaissance de caractères sur un texte bien formé :
On va juste vérifier que ça fonctionne à l’aide d’une image de « Lorem Ipsum » prise sur Wikipédia.
~# wget https://upload.wikimedia.org/wikipedia/commons/5/57/Lorem_Ipsum_Helvetica.png
Puis en saisissant le plus simplement du monde dans la ligne de commande :
~# tesseract Lorem_Ipsum_Helvetica.png stdout
Et voilà le résultat :

Helvetica Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet.
Et comment ça marche ?
Assez simplement à l’aide des réseaux de neurones… je déconne, c’est assez complexe. Et comme un bon lien vers Wikipédia vaut mieux qu’on long discours je vous renvoi vers la page de l’encyclopédie en ligne sur le sujet. En plus, vous avez les sources : débrouillez-vous !
Reconnaissance de caractères sur des images moins évidentes ?
Bon, comment Tesseract s’en sort sur des morceaux de texte moins bien formé ? genre un captcha :
~# wget https://upload.wikimedia.org/wikipedia/commons/b/b6/Modern-captcha.jpg
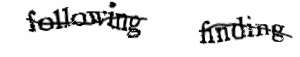
bein, pas top pour l’instant :
~# tesseract Modern-captcha.jpg stdout Empty page!! Empty page!!
On obtient à peine mieux si on l’aide un peu (il se trompe bien, mais au moins il a trouvé des choses) :
~# tesseract Modern-captcha.jpg stdout -l eng -psm 7 M WE
Par contre, si on retente sur un captcha beaucoup plus faible ?
~# tesseract weakCaptcha.png stdout 7rr95
Là on a aucune erreur, c’est immédiat.
Et si on essai sur un d’une difficulté intermédiaire ?
~# tesseract MediumCaptcha.jpg stdout

Rien non plus…
Alors à se moment, on se dit que c’est pas super puissant comme outils pour le pentest. Sauf que, vous avez zappé le traitement d’image que l’on peut faire sur le Captcha avant de le filer à tesseract pour faire la reconnaissance de caractères.
Prétraitement de l’image
Sur l’exemple au dessus, j’ai appliqué un simple filtre de niveau sur l’image, c’est à dire :
- passer l’image en noir et blanc ;
- et garder tout les pixel qui dépasse la valeur 90 (sur 255).
Ça se fait pour ainsi dire instantanément sur un pc, ça demande en gros 30s à un gamin de 12 ans dans PAINT.NET (Menu Ajustement->Niveau), et ça fait partie des premiers trucs qu’on apprend dans un cours de traitement d’image.
Et donc on la reconnaissance sur l’image traitée avant, et magie :

~# tesseract MediumCaptchaProcessed.jpg stdout 1647
Comme quoi ça ne tient pas à grand chose au final et un attaquant un peu malin peu facilement contourner , à l’aide de la reconnaissance de caractère, ce genre de système « Antibot » mis en place par un admin pas trop motivé, ou pas bien au courant.
Conclusion
Pour conclure, j’espère que vous avez compris que le reconnaissance de caractères c’est un truc qui marche. Que Tesseract est aujourd’hui livré en standard dans toutes les grosses distrib linux et que globalement si on branche 2 neurones avant de lancer le truc, on peut « bypasser » la plupart des systèmes de protection en quelques essais. Et que, enfin, en dehors du contexte du pentest, si on souhaite simplement récupérer le texte d’un document scanné propre, c’est aussi simple que de dire :
~# tesseract fin_article.png stdout -l fra
Byz à tous et joyeuses fêtes !

Bonjour,
J’aimerai savoir s’il vous plait est ce que ça marche aussi pour l’identification des passeports
Merci
Bonjour,
Oui tout a fait, ce genre de technique peut-être utilisé dans tous les logiciels de gestion de documents papier.
Après je tiens à préciser qu’il s’agit identification et numérisation des informations du document et pas d’authentification de la validité du document.
Cordialement,
bonjour,
svp je veux connaitre exactement le principe de tessract pour le traitement de l’image depuis l’acquisition jusqu’au la reconnaissance ?
http://fr.lmgtfy.com/?iie=1&q=OCR
Bonjour
En ce qui me concerne. j ai insttaller alfresco 5.1 sur centos 6 dans le repertoire /data.
Question: Dans quel sous repertoire de /data dois-je installer toute cette procedure?
Pas la moindre idée, c’est un post sur tesseract-ocr, pas la config d’alfresco…^^
Juste une question y a t-il moyen de compiler avec autre chose que automake build-essential libtool car en ce qui me concerne je suis sous window 7 et j’ai crue comprendre que buil-essential n’etais pas compatible avec windows!
Sinon le tuto a l’air est super bien fait 🙂
Excellente question ! Si votre objectif est simplement d’utiliser tesseract, je ne m’embêterai pas à le compiler et j’utiliserai un des installeurs proposés par le projet :
https://github.com/tesseract-ocr/tesseract/wiki#windows
Si l’objectif est bien de compiler tesseract sous Windows (quel drôle d’idée au passage), je ne sais pas pour le coup…
Sinon à défaut, une VM Debian ou Ubuntu dans VirtualBox fera l’affaire avec mon tuto.
Effectivement. Sur le site ils disent qu il est preferable de faire un pre-traitement avec par exemple scantailor. Je le conseille egalement, la reconnaissance est bien meilleure !
Pour info, j’ai jeté un œil à scantailor dans cet article. Ca me parait très bien pour scanner des pages de livres ou de magazine à la chaine. Par contre ca m’a paru peu adapté pour une approche sécu/hacking. A voir si on peu extraire les traitement individuel de scantailor dans un script ? via des lib comme imagemagick par exemple ?
Bonjour,
Excuser‑moi, il y aurai‑t‑il une tranformation unique possible pour ce genre de captcha ?
Nice post.
But what would be the distortion in order to get those kind of captcha recognized by Tesseract :
https:// cloud.githubusercontent.com / assets / 3824869 / 16745722 / 6d7e34bc-47b7-11e6-944d-39fc4c5f3ba4.jpeg
https:// cloud.githubusercontent.com / assets / 3824869 / 16745723 / 6d81c488-47b7-11e6-90b2-cc7c602e33a3.jpeg
https:// cloud.githubusercontent.com / assets / 3824869 / 16745724 / 6d88035c-47b7-11e6-958f-b969e8d3f31f.jpeg
https:// cloud.githubusercontent.com / assets / 3824869 / 16745726 / 6dd24c64-47b7-11e6-86e4-e25f47beb76f.jpeg
https:// cloud.githubusercontent.com / assets / 3824869 / 16745725 / 6dbfaa46-47b7-11e6-83c9-5f612498c313.jpeg
https:// cloud.githubusercontent.com / assets / 3824869 / 16745727 / 6dde54c8-47b7-11e6-873f-171e5fa39d92.jpeg
Je ne sais pas. l’objectif des captchas étant justement d’empêcher les programmes comme tesseract*ocr de fonctionner, il est clair que chaque « type » de captcha nécessite une analyse fine.
Dans votre cas, si les distorsions sur les images indiquées reste dans un nombre limité de type possible (genre : en U, en C, en M etc. ) :
l’utilisation d’un bibliothèque comme imagemagick (https://www.imagemagick.org/) avec 2 ou 3 « reverse distorsion » types pourrait permettre, je suppose, d’obtenir des résultat intéressants en donnant juste le coup de pousse qu’il faut à tesseract pour augmenter ses chances de réussite. En répétant les essais et en re-générant le captcha en cas d’échec, on devrait réussir à passer en quelques tentatives ?
Je rappelle qu’il s’agit d’un article à vocation académique, à ne pas utiliser à des fins potentiellement malveillantes.
Tenez moi au courant de vos résultats…
Cordialement.
Toujours aussi intéressant tes tp
Thanks